Deep Learning & How to Choose the Right Model
Convolutional Neural Network (CNN)
- Based (loosely) on concepts taken from models of how the human visual cortex operates.
- Rely on convolutional operations to provide some translation invariance.
- Learn visual features in a hierarchical fashion.
- Also proven useful in non-vision applications.
![]()
- Convolutional Neural Networks https://anhreynolds.com/blogs/cnn.html
- Understanding Convolutions: https://towardsdatascience.com/intuitively-understanding-convolutions-for-deep-learning-1f6f42faee1
- Convolution Arithmetic: https://github.com/vdumoulin/conv_arithmetic
- 10 CNN Architectures: https://towardsdatascience.com/illustrated-10-cnn-architectures-95d78ace614d
Image from https://anhreynolds.com/blogs/cnn.html
Convolution
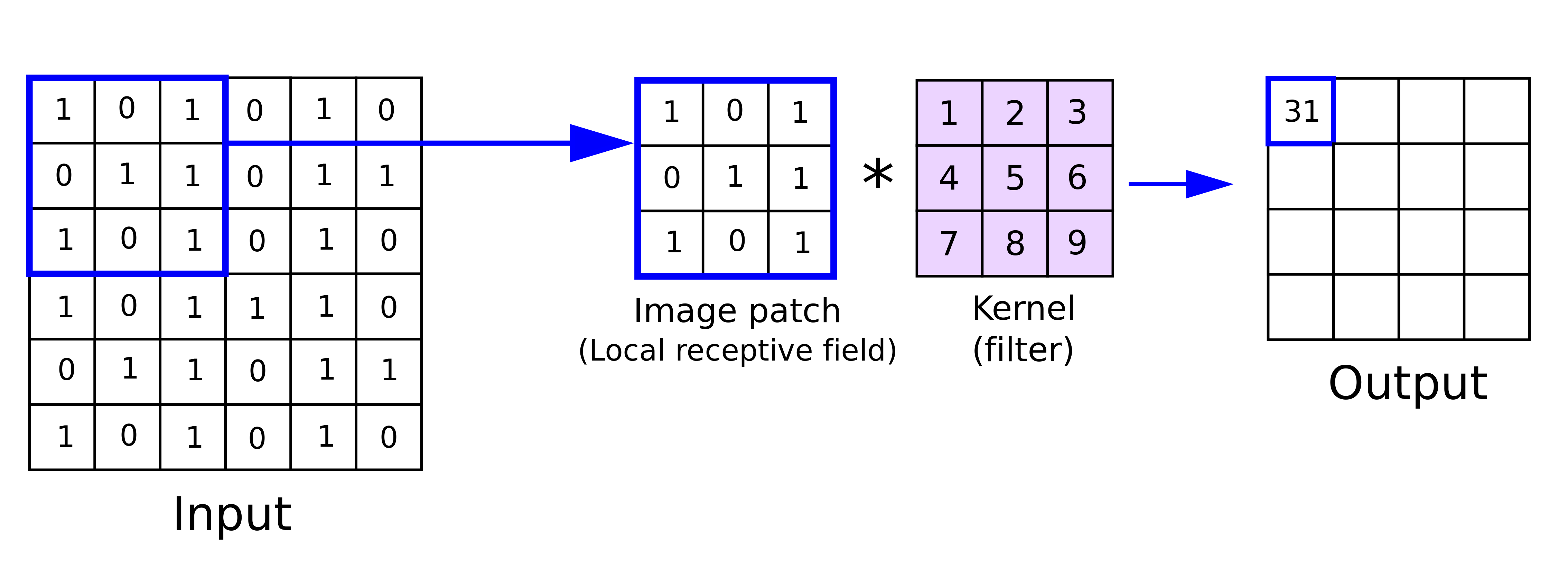
Each \(N\times N\) patch in the Input is “compared” (via dot product) to the filter (or kernel) and the result creates a single pseudo-pixel in the Output.
Image from https://anhreynolds.com/blogs/cnn.html
Convolution Filters : Edge detection
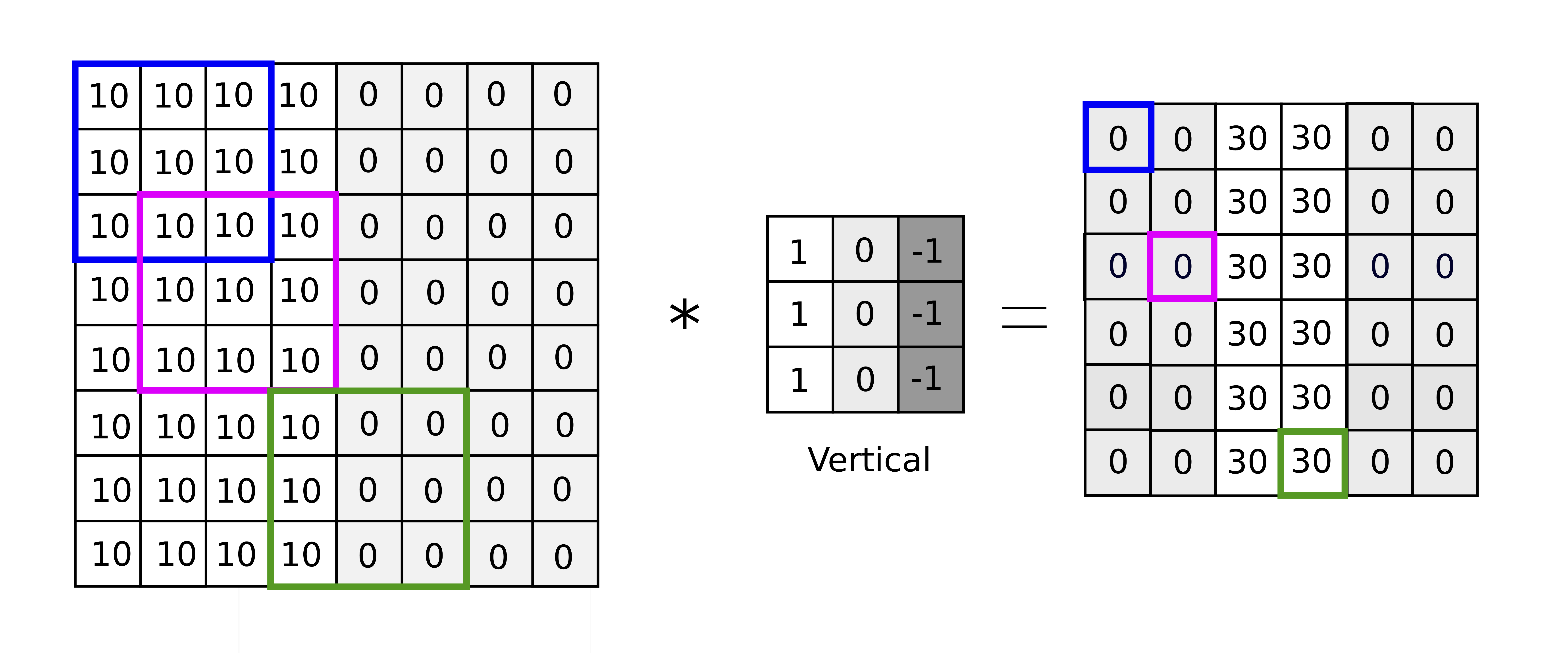
An example kernel that will provide vertical edge detection. Notice how it responds highly at the boundary between the “lighter” and “darker” pixels in the input.
In practice, we don’t hand-craft the filters—we let the network learn them. (In other words, the values in the filter are weights (or parameters) in the model.)
Image from https://anhreynolds.com/blogs/cnn.html
Recurrent Neural Network (RNN)
- Typically used for timeseries data and Natural Language Processing.
- The output for each new input also depends on previous input(s).
- Also work well when mixed with CNNs for visual tasks.


- Illustrated Guide to RNNs: https://towardsdatascience.com/illustrated-guide-to-recurrent-neural-networks-79e5eb8049c9
- Understanding RNNs and LSTMs: https://towardsdatascience.com/understanding-rnn-and-lstm-f7cdf6dfc14e
- RNN Effectiveness: https://karpathy.github.io/2015/05/21/rnn-effectiveness/
RNN Image: https://upload.wikimedia.org/wikipedia/commons/b/b5/Recurrent_neural_network_unfold.svg
LSTM Cell image: https://upload.wikimedia.org/wikipedia/commons/5/56/LSTM_cell.svg
Autoencoder
- Autoencoder is one of the few unsupervised deep learning models.
- It learns to reproduce its input as precisely as possible by first encoding it to a latent feature-space representation, then decoding that representation back to the original dimensionality.
- Can be used for compression, denoising, and more.
- Can be used for pre-training weights for “few shot learning”.

- What is AE used for?: https://towardsdatascience.com/auto-encoder-what-is-it-and-what-is-it-used-for-part-1-3e5c6f017726
- Autoencoders (Stanford): http://ufldl.stanford.edu/tutorial/unsupervised/Autoencoders/
- Autoencoders: https://www.jeremyjordan.me/autoencoders/
- LSTM Autoencoders: https://machinelearningmastery.com/lstm-autoencoders/
Autoencoder Image: https://upload.wikimedia.org/wikipedia/commons/2/23/Autoencoder-BodySketch.svg
Generative Adversarial Network (GAN)
- Combines the concept of a discrimanative model with a generative model.
- Trains both models together - each tries to “fool” the other.
- End result is a pretty good generator and a pretty good discriminator.
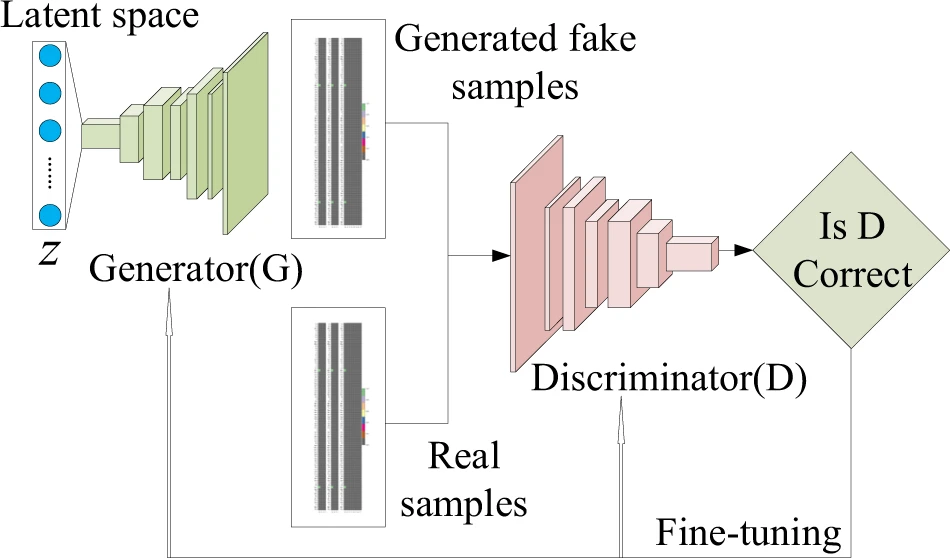
Image: Dan, Y., Zhao, Y., Li, X. et al. Generative adversarial networks (GAN) based efficient sampling of chemical composition space for inverse design of inorganic materials. npj Comput Mater 6, 84 (2020). https://doi.org/10.1038/s41524-020-00352-0
Transformer Networks
Transformer networks are a type of neural network architecture used in natural language processing (NLP) tasks such as machine translation and sentiment analysis.
The key feature of transformer networks is the self-attention mechanism, which allows the network to weigh different parts of the input sequence differently based on relevance. This is used instead of recurrent state (as used in a RNN) to model the time-series relationship.
![]()
Images: A. Vaswani et al., “Attention Is All You Need,” arXiv:1706.03762 [cs], Dec. 2017 [Online]. Available: http://arxiv.org/abs/1706.03762.
Learn More
Deep Learning Book (by Ian Goodfellow, Yoshua Bengio, and Aaron Courville) - a comprehensive textbook covering a wide range of deep learning topics. https://www.deeplearningbook.org/
Papers with Code - a website that aggregates recent research papers and provides open-source implementations and evaluation metrics available with each of them. https://paperswithcode.com
MIT Deep Learning Series - a collection of video lectures by prominent researchers, designed to give a broad overview of the field of machine learning and deep learning. https://deeplearning.mit.edu/
Coursera Deep Learning Specialization - a series of online courses providing a graduate-level introduction to deep learning. https://www.coursera.org/specializations/deep-learning
TensorFlow.org - a popular open-source platform for constructing and training machine learning models, including deep learning. https://www.tensorflow.org/
PyTorch.org - another popular open-source platform for constructing ML models. Probably more popular than Tensorflow among ML researchers at the moment. https://pytorch.org/

Deep Learning & How to Choose the Right Model

{kind=link}